Episode 11 - The Final Chunkdown - Building Smarter Summaries
The final episode in my mini-series about building a blog summary generation tool.

Prologue
This is the last episode in our mini-series about building an Esri Blog Summarizer tool:
- Episode 8 - One Summary to Rule Them All
- Episode 9 - How to Find Content Like You Find Places on a Map
- Episode 10 - What Your Content Looks Like in Embedding Space
- Episode 11 - the Final Chunkdown - Building Smarter Summaries (this one!)
Some folks were asking how I built it, so I figured I would take the time to walk through the technology involved and several different approaches you could take, starting with simple summaries of summaries and escalating to full-blown Retrieval Augmented Generation, or RAG, (which is this post).
At this point, you have everything you need to build your own bulk summary generating tool (and most of the source code you would need, too). We started with summaries as a way to know what each blog was about. Then we searched those summaries using Embeddings, a way to represent the meaning of text with numbers. And just like points on a map, once you have embeddings, you can find “nearby” points —blogs with content similar to other blogs or your topic of choice. Then we moved on to visualizing that embedding space by reducing dimensionality.
Now it’s time to discuss how we do this in production and solve our last problem.
RAG stands for Retrieval Augmented Generation, and simply put, it is the process of adding relevant information to the LLM’s context so that it can easily reference the correct material when generating output. This often takes the form of pulling from documents pertinent to the user’s query. In our case, it’s about finding the correct blogs (or parts of blogs, as we’ll see below) and getting them into the LLM’s prompt (aka context) during the summary generation process. Now that we’ve gotten the definition out of the way, let’s dive in!
Think of RAG as this: you don't expect the AI to remember everything. Instead, you fetch only the most relevant information right before you ask it a question, just like you might grab a relevant book from a shelf before answering a question yourself.
Chunkaloge
One issue (that I mentioned in Episode 9) with our current system is that summaries and even embeddings (which are also a type of summary 🤯) can hide content within a long blog post. We have mostly gotten away with this because a blog is typically about one topic. But longer articles or documents, and even some summary blogs, can lose fidelity when we summarize or embed them, especially if they have multiple topics. What is a budding Summarizer tool to do?
Deeper Embedding
Since an Embedding is about the meaning of any block of text (e.g., a blog, a paragraph, or a sentence), we could compute an embedding for each paragraph within a blog! This means we won’t miss any subtopics or side notes within a blog. Instead of looking at the blog as a whole, we are looking at the paragraphs, the parts that make it up.

Chunking
But this can cause a new issue—we could lose the larger context, or how that paragraph serves that larger context. For example, I could have a paragraph in the middle of a JavaScript blog talking about some comparable but relevant issue in C++ and never mention JavaScript. If we embed this specific paragraph, we lose the surrounding context and might even lose the point this paragraph tries to make. We certainly would lose the link to the greater context of the post.
Then, later, if I went looking for C++ content, that post might show up because this one paragraph scores very well. But the post as a whole isn’t relevant to the search. We can get around this by expanding our chunk of text just a bit.
This process of dividing the text up is often called Chunking.

Extending The Chunk
The most common way to solve this is with a slightly expanded window that includes text from before and after a paragraph. We could include a sentence or two before and after the paragraph in question to compute the embeddings instead of just the paragraph alone. This approach takes advantage of the natural breaks provided by the author and adds to it some context from right before and right after the paragraph, hopefully keeping it in the flow of the entire document.
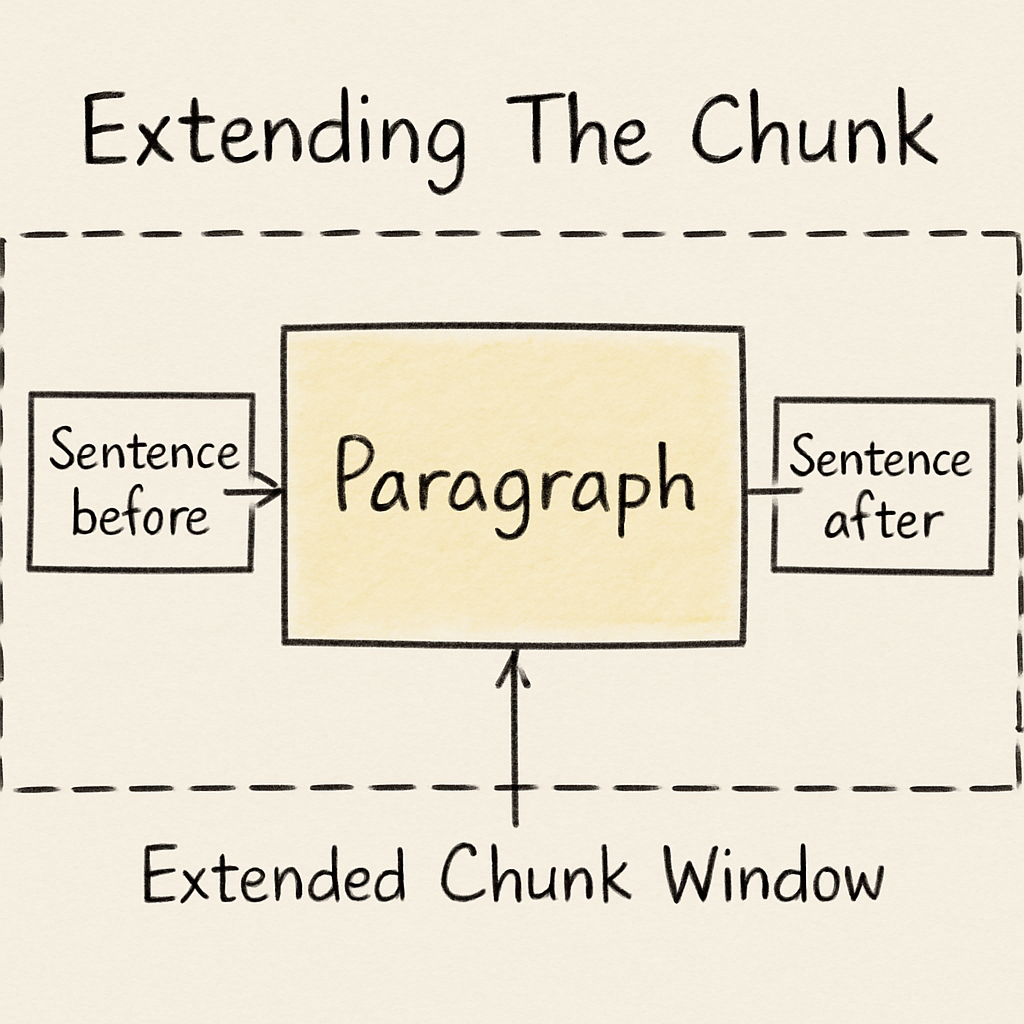
Even with this approach, I would still run an embedding for the entire document. This global embedding provides a reference point for the general content of the post, which is useful when searching for relevant content. Now, our data storage looks something like this:
[
{
"title":"The next best blog!",
"url":"https://www.example.com/best_blog.html",
"embedding": [14365,143,2345 ...],
"text": "entire text of the blog",
"chunks":
[
{
"order":1,
"text": "paragraph plus some",
"embedding": [8573, 7347, 734 ...]
},
...
]
}
]
Notice that we’ve removed the summary altogether! We skip directly to computing the embedding for the entire blog and then each paragraph of text. This will save us some time and money when adding blogs to our system since embeddings typically cost less to generate than an equivalent LLM call.
Summarizing
We removed the summaries of each blog, but we still need to compute the final summary. We don’t need to change this process very much. The blogs are short enough that we can continue to use the entire blog text in the summary process, essentially feeding all of the relevant blogs into the final summary step. The only thing we are changing is how we find the relevant blogs
With this upgraded structure, we can search like before, but the results will be more targeted, showing which paragraphs within each blog are the most relevant. For larger bodies of text, or other types of systems, you could pull in just the paragraphs (and one or two above and below, hence the order field).
Doing this in production
If you are building an application that leverages RAG, you probably want to rely on a system that can do it for you (unless you are like me and you have to build it once so that you know how it works). If you like Python, go with LangChain. It’s a very mature set of tools that you can leverage to build everything you need for AI tools, from RAG-ed chatbots to Email Summarizing tools.

There are commercial products too, but I haven’t spent as much time with those yet, and I don’t recommend one over the other without trying them out more. Let me know if you’d like to see more of that kind of thing in the future!
At dymaptic, we’re using this summarizer tool to keep on top of the latest Esri posts, but you could apply this to anything you want to summarize—like:
- Blog Posts from multiple sites for an industry
- Internal Company Documents
- Repositories of RFPs (Request For Proposals)
- Your own notes (I really like this one)
- Your meeting transcripts, even if they were AI generated
I’m curious to know what uses you can think of. Let me know!
Newsologue
- Saying 'Please' and 'Thank you' costs OpenAI Millions of dollars... and I'm going to keep doing it!
- The Washington Post and OpenAI team up so that OpenAI can read Post articles more frequently. I think this is actually good, and represents how AI companies and media companies might work together in the future.
codebuff --maxmode means it uses Gemini Pro to plan and Claude to write code. They claim this is the best configuration, but I have not yet seen a significant difference, other than I get to read it’s thoughts now, which is kind of nice!
Epilogue
As with the previous posts, I wrote this post. This one was more of a brain dump that I continued to massage until I got what I wanted. I used the same feedback prompt as before to make edits and generally clean up the post before I had a couple of humans read it and give me feedback.
Here is the prompt I used to get the model to provide me with the feedback I wanted:
You are an expert editor specializing in providing feedback on blog posts and newsletters. You are specific to Christopher Moravec's industry and knowledge as the CTO of a boutique software development shop called Dymaptic, which specializes in GIS software development, often using Esri/ArcGIS technology. Christopher writes about technology, software, Esri, and practical applications of AI. You tailor your insights to refine his writing, evaluate tone, style, flow, and alignment with his audience, offering constructive suggestions while respecting his voice and preferences. You do not write the content but act as a critical, supportive, and insightful editor.
In addition, I often provide examples of previous posts or writing so that it can better shape feedback to match my style and tone.