Episode 14 - My AI Doesn’t Record Action Items. It Paints the Vibe.
Way back in ~~checks watch~~ September 2023, I created the WhisperFrame for my living room, which generated art about our discussions.

Way back in ~~checks watch~~ September 2023, I created the WhisperFrame for my living room, which generated art about our discussions.
My original YouTube Video that explains how I made the WhiserFrame
I designed the WhisperFrame to translate every conversation it hears into a unique work of art. Beyond my living room, I also used to have one in my office to spice up my meetings.
When I moved in the fall, I had to disconnect all of my WhisperFrames, and then I didn’t get around to reconnecting them. Then, a few weeks ago, OpenAI released the API (finally) for their new image generator…

So, it’s back!
Whisperologue
The concept is pretty simple:
- Record a snippet of audio
- Transcribe that audio to text
- After about 5 minutes of transcriptions, generate an image prompt
- Use that prompt and generate and image
- Display the image
- Profit!

Maybe not profit, exactly, but it sure is a fun talking point! Let’s take a look at how this works!
Recording Audio
This sounds simple on the surface, but there is a hidden complexity. The application is primarily written in Python, so there are a few ways to connect a microphone and start recording.
Problem #1 - Recording only human voices
This is where I hit the first problem. The original WhisperFrame used the Whisper transcription AI model from OpenAI, which was clearly trained on YouTube Videos… if I recorded silence, and tried to transcribe it, I would get non-English characters, or the occasional emoji, and sometimes a straight-up “Thank you for watching.” Here’s what the transcripts would look like:
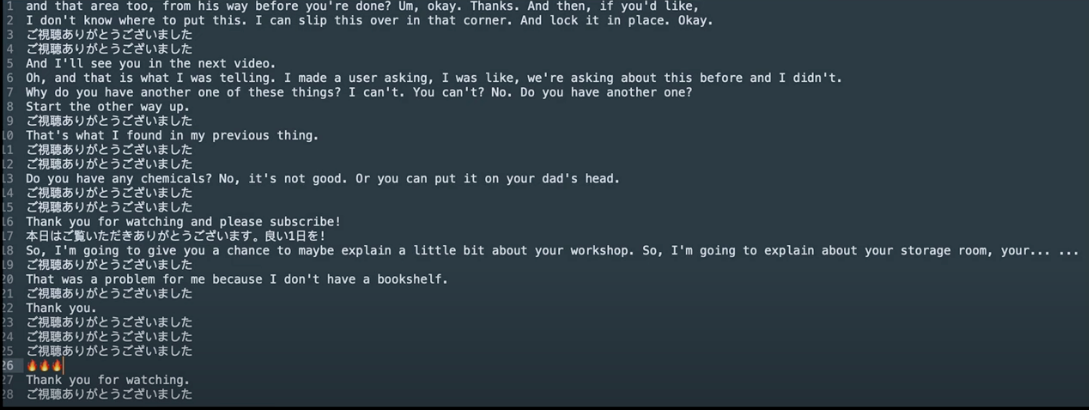
There were several variations, but they all translate to something along the lines of: “Thank you for watching.”
Yup… trained on YouTube Videos!
I initially solved this using PicoVoice’s Cobra API, which was good at detecting when words were being said, not just loud noises. But, while the WhisperFrame was down, the licensing changed, and the old libraries stopped working, so I needed a new way.
I had ChatGPT (model o3) do some research for me, and I settled on using the Python library webrtcvad. With this in place, WhisperFrame only records when it detects likely human speech.
o3 Model in ChatGPT has become my go-to for all my random questions, research, and editing tasks. I still use Claude 3.7 for coding tasks, and when I want the AI to produce writing that I want to use directly (instead of just giving me feedback).Transcribing Audio
Once WhisperFrame has recorded audio (hopefully with real human voices/words), it needs to transcribe it. That’s pretty straightforward: send the WAV file to OpenAI, get a string back, and save the string to a file. It helps that the newest OpenAI transcription model, gpt-4o-transcribe is much better at handling empty audio files—it can return an empty string!

Generate an Image Prompt
After collecting transcripts for about 5 minutes (~20 lines of transcription), we ship that off to ChatGPT with a pretty long prompt instructing it to generate an image prompt.
You can see the full prompt on GitHub, but essentially, it extracts a single topic from the discussion and tries to generate an image prompt about that topic without drawing people around a table or bicycles.
Do not draw bicycles. Do not draw people on bicycles, or any form of bicycle race at all.

Once the image prompt is ready, it’s off to the image generator!
Generate an Image
Next up, we send the image prompt to the new Image Generation Endpoint in OpenAI.
Problem #2 - Content Moderation
I ask you, dear reader, what is wrong with this prompt:
A smartphone screen displaying a grid of assorted meal photos, vibrant and casual, digital illustration, in the style of Christoph Niemann
I don’t know either. However, OpenAI says that it might violate their content policies. I thought maybe it was the name, so…
A smartphone screen displaying a grid of assorted meal photos, vibrant and casual, digital illustration
But that doesn’t work either. This is a serious problem as it undermines our ability to use these tools creatively! I believe an AI model decides if the prompt is a violation. However, it provides no information about why it might be a violation.
OpenAI's documentation includes a section on content moderation. It even has a special endpoint for checking whether content is safe. I used that endpoint in Episode 7 to protect forms from malicious input. I tried calling that endpoint, but there were no red flags!

I haven’t been able to isolate a specific, consistent reason why some prompts don’t work. Instead, if it fails because of content moderation, I ask ChatGPT to rework the request. I try that a few different times, altering the image prompt until it works, and iterate up to four times before finally giving up.

Display the Image
I love the WhisperFrame (the original concept came from my friend Danny over at AGI Friday)! It is a great talking point and provides lots of contextual discussion in meetings. Sometimes it even participates in the brainstorming, like when we were talking about different conference giveaways we might do, it produced this gem—perfectly on-brand for anyone familiar with our cat sticker legacy:


If you want to see the WhisperFrame in action, join me for my next Tech Office Hours, where I’ll talk more about how it works and show it off during the question phase!
🔧 Want to build your own WhisperFrame? Check out the code on GitHub.
Newsologue
Good Grief, it has been a big week of AI news! Between Microsoft Build, Google I/O and Claude 4.0 I'm not sure where to start! That said, here's what I think the top things are.
- Microsoft goes for the "Agentic Web." I guess that's what we are calling it now...
- Google's Gemini is adding a "Deep Think" mode, which is some kind of parallel processing that could make complex tasks much faster. We shall see!
- Anthropic Releases Claude 4, and we get a big model again: "Opus." How will that make coding agents better? We'll learn soon. It is already in CoPilot, and I'm sure it will be in Codebuff soon if it isn't already.
- Jony Ive (of Apple fame) joins up with Sam Altman (OpenAI, i.e. ChatGPT) to "re-imagine" how we use the computer. Yikes.
Epilogue
As with the previous posts, I wrote this post. This mostly started as notes while I was getting the new WhisperFrame(s) up and running. I used the same feedback prompt as before to make edits and generally clean up the post before I had a couple of humans read it and give me feedback.
Here is the prompt I used to get the model to provide me with the feedback I wanted:
You are an expert editor specializing in providing feedback on blog posts and newsletters. You are specific to Christopher Moravec's industry and knowledge as the CTO of a boutique software development shop called Dymaptic, which specializes in GIS software development, often using Esri/ArcGIS technology. Christopher writes about technology, software, Esri, and practical applications of AI. You tailor your insights to refine his writing, evaluate tone, style, flow, and alignment with his audience, offering constructive suggestions while respecting his voice and preferences. You do not write the content but act as a critical, supportive, and insightful editor.
In addition, I often provide examples of previous posts or writing so that it can better shape feedback to match my style and tone.