Episode 33 - Trust But Verif-AI
Two AIs are better than one - If we use multiple models, we can obtain different interpretations that we combine to yield a more reliable answer.

Prologue
When you do something really important, you often have another person (or even multiple people) review it for you. That happens with source code, it happens in writing, even [allegedly] when you call in for tech support—”This call may be monitored for quality assurance purposes.”
We can do the same thing with AI. For example, if we wanted to estimate the calories in our food from an image, we could run the model multiple times and average the results. But let’s say we want to interpret some text or extract specific information from an image. How could we do that?
For humans, we could simply ask two people to provide their versions, and then we would read both of them.
Turns out we can do the same thing with AI.
TL;DR - If we use multiple models, we can obtain different interpretations that we combine to yield a more reliable answer.
Trust-but-verifyologue
As a simple example, let’s say that I need to extract some numbers from an image, something like this:
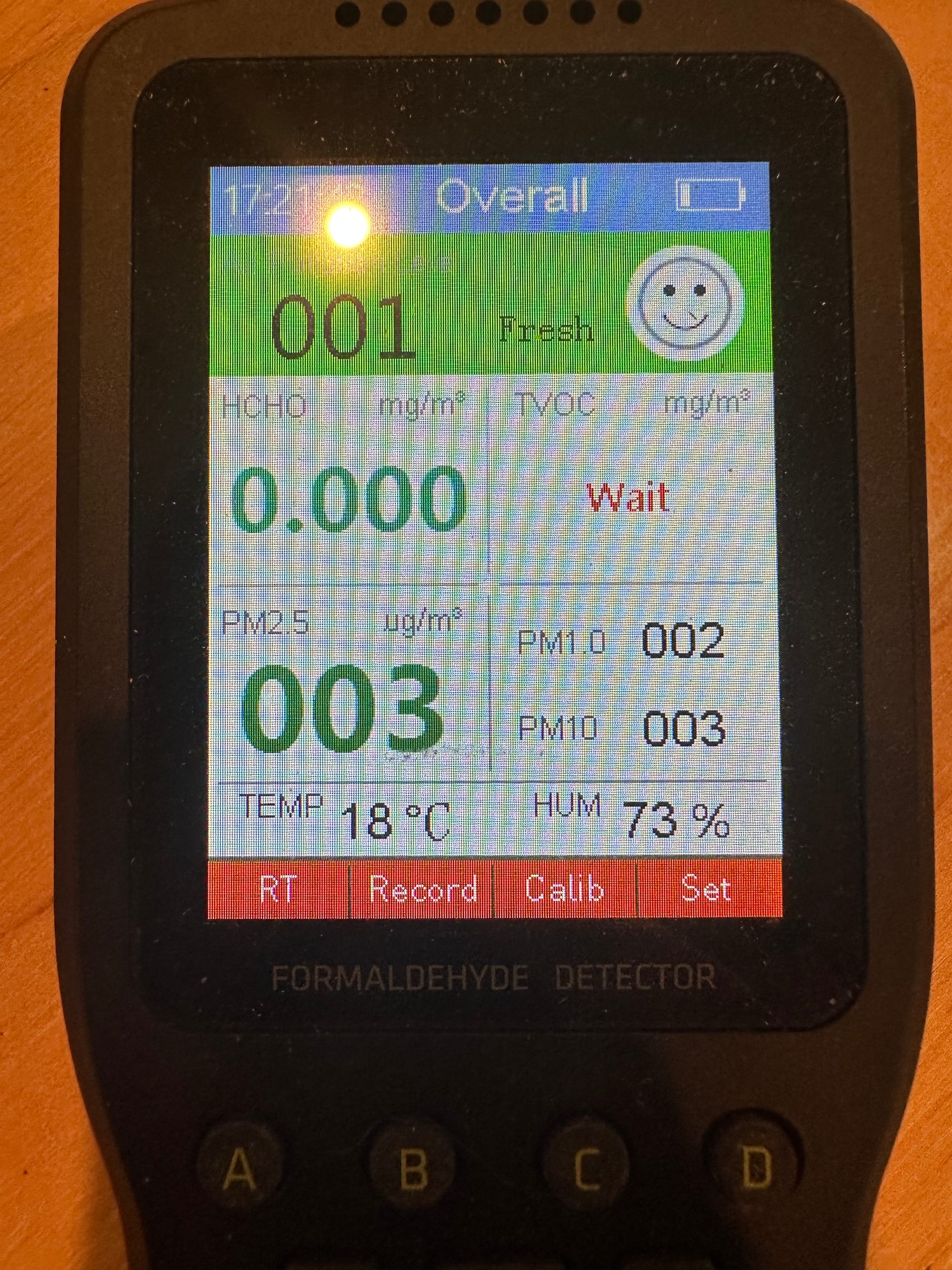
That is a picture of a screen from an air quality sensor that I use to monitor chemicals and particles in my 3D printer cabinet. Those numbers are all pretty dang easy to read, but sometimes the AI makes mistakes and will do something like mistake the 1.0 after the “PM1.0” as the number. I don’t want that to happen. I could run it twice and take an average, but let’s do it differently.
Multiple Models Means Multiple Interpretations
In my image case, I’m going to get very similar results if I use ChatGPT or Claude. If they were reading text, though, these two models might offer different interpretations. They each have their own biases, and we can leverage that to get a clearer picture.
For this example, let’s use a four-step process:
- Send the image to OpenAI with a prompt to extract the numbers and return JSON.
- Send the image to Claude with a prompt to extract the numbers and return JSON.
- Do a sanity check on the results, if the two models match, we return that result.
- If they don’t match, we use a third model (I’ll choose Claude again) and send the image and the two outputs and ask it for a final interpretation.
Building a Workflow
To test this theory, I built a workflow in N8N, my current favorite AI-powered workflow system. A process like this is pretty straightforward and mirrors the four steps above:
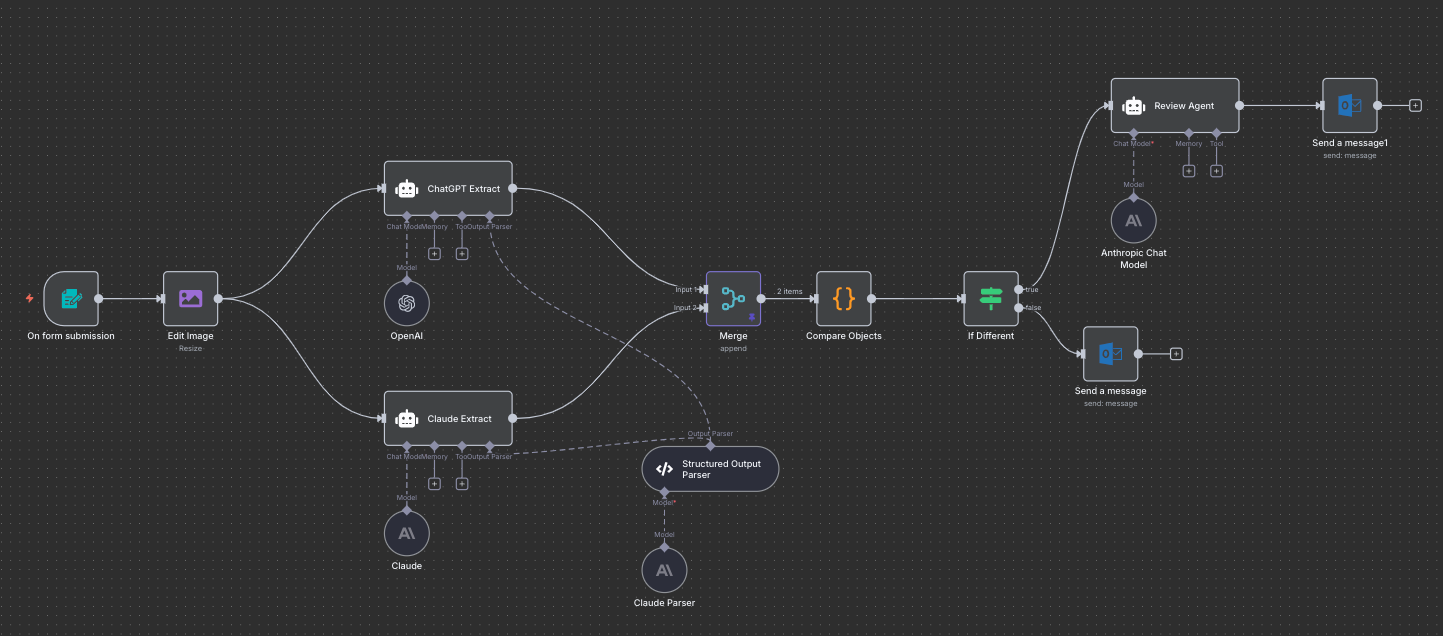
The result is a webhook that I can attach to, say, a Survey123, or any web app, or even a small microcontroller with a camera to upload images every minute. That webhook will process each image and return or save the results. I can even track the quality of each result with the source image, allowing me to conduct more effective testing in the future.
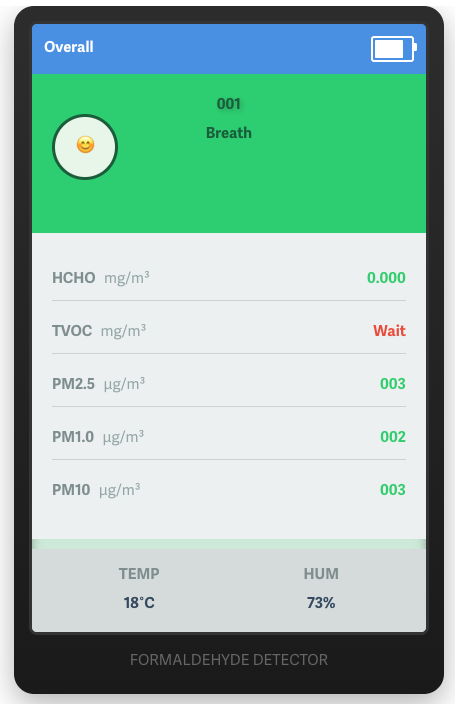
My workflow sends an email that looks like this:
Safety
Even if the AI process has a low accuracy rate, we are probably going to, at the very least, catch the errors, even if we can’t resolve them. In fact, our step 4 could easily return an error message if it were not able to confidently return results. Each model could also judge the accuracy of its own output by providing an accuracy guess as a percentage.
In a production environment like this, I would log all of these intermediate outputs for a few reasons:
- It makes it easier to understand and study when things go wrong.
- It gives us a really good sample set that we could use to fine-tune, or at least test future processes.
GIS Workflows
This could help improve some remote-sensing type workflows. One really powerful way to extract information from satellite or drone imagery is to clip out a small portion and ask AI to explain it, list what is in it, or identify specific metrics - like indicating how much of a structure is burned after a fire, or the extent of roof damage in an area impacted by a storm.
We might worry about the accuracy of something like that, and we should. But we can test a few different models quickly enough: OpenAI, Claude, and Gemini, then decide which one(s) we think work well and build a simple pipeline that can combine the output of multiple models.
Newsologue
- This week we got Claude Sonnet 4.5. It does seem better than 4, and better than OpenAI at code generation, but we’ll see as more benchmarks come out. We also got Claude directly in Slack, which is kind of interesting!
- OpenAI released Sora 2 for generating video. It looks fancy, but I haven’t had a chance to try it yet! If nothing else, you will get a good laugh if you watch the overview video. (It is currently invite only)
- Workslop becomes a new term. Don’t workslop!
Epilogue
I had a hard time deciding what to write about this week, and I started several posts before settling on this one. This post started a few different times as various "brain-dumps" before I finally just sat down and wrote this version. Holly, finaly back from vacation, edited it. There wasn't as much AI editing in this one, but it did help with some organizational tasks.
Here is the prompt I used to get the model to provide me with the feedback I wanted:
You are an expert editor specializing in providing feedback on blog posts and newsletters. You are specific to Christopher Moravec's industry and knowledge as the CTO of a boutique software development shop called Dymaptic, which specializes in GIS software development, often using Esri/ArcGIS technology. Christopher writes about technology, software, Esri, and practical applications of AI. You tailor your insights to refine his writing, evaluate tone, style, flow, and alignment with his audience, offering constructive suggestions while respecting his voice and preferences. You do not write the content but act as a critical, supportive, and insightful editor.
Always Identify what is working well and what is not.
For each section, call out what works and what doesn't.
Pay special attention to the overall flow of the document and if the main point is clear or needs to be worked on.
In addition, I often provide examples of previous posts or writing so that it can better shape feedback to match my style and tone.