Episode 28 - Google’s AlphaEarth Changes GIS, a little
AlphaEarth is a set of pre-computed embeddings across the entire Earth (over time) that makes it possible to search for similar locations. But what does that mean for GIS?

Prologue
A few weeks ago, Google announced a new AI offering: AlphaEarth. They made numerous statements about how earth-shattering and revolutionary it is. And it is very cool, but let’s take a closer look at what it actually is.
TL;DR - AlphaEarth is a set of pre-computed embeddings across the entire Earth (over time) that makes it possible to search for similar locations.
AlphaEarthologue
The key to AlphaEarth is embeddings, so we need to revisit and understand what they are before we can grasp what this really means. I’ve discussed embeddings before, but I’ll recap them here.
What is an embedding?
Embeddings are a way to represent the meaning of something by using a vector (a list of numbers). One simple way to think about this is using an address. An address is a description of a location. We can use a process called Geocoding to convert that description into a latitude and a longitude. The resulting latitude/longitude pair represents the meaning of the address—the location on the Earth. Once we have that latitude/longitude pair, we can do all kinds of interesting things, such as finding other nearby locations and computing distances.
Just like we can use GPS to locate ourselves on the Earth, and, from there, compute meaning about that location—embeddings do that for ideas.
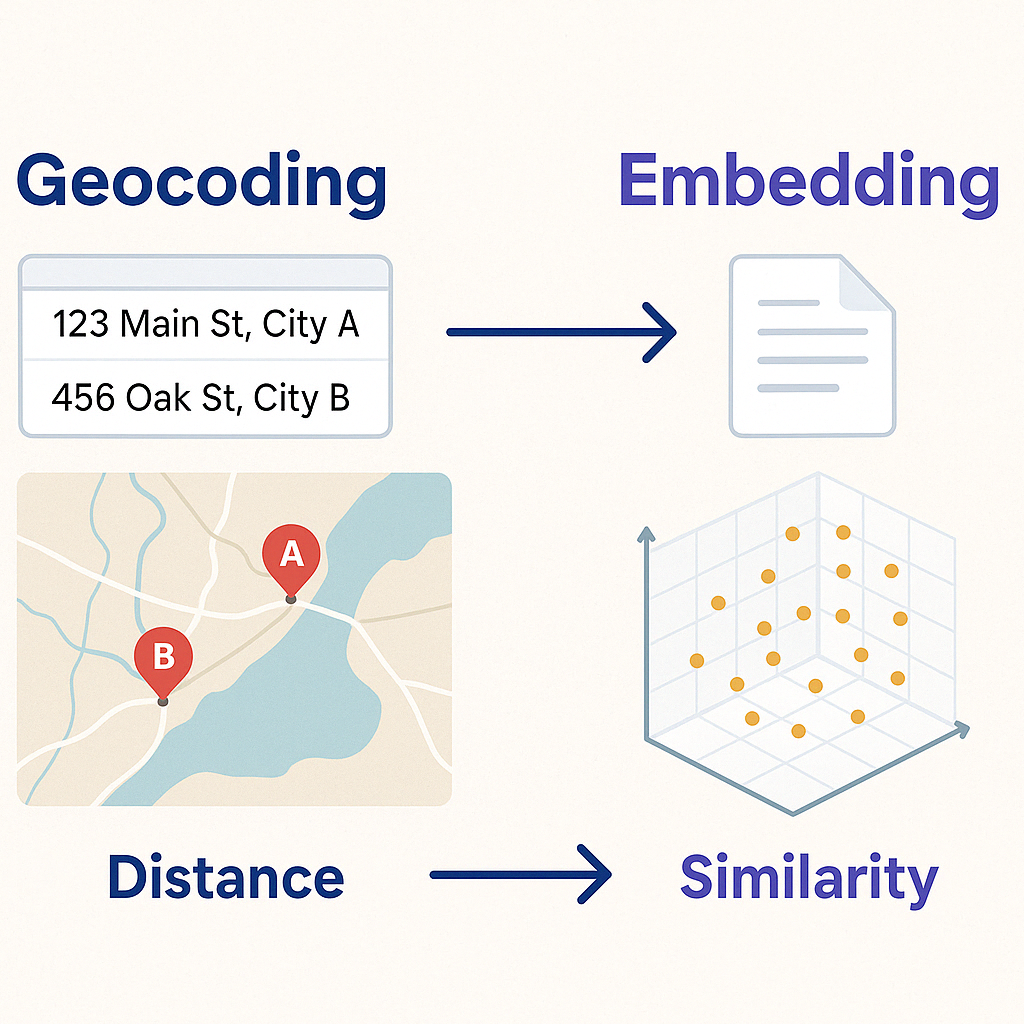
That is exactly how an embedding works—embeddings just have more numbers (sometimes hundreds or thousands) so that they can represent the meaning of some input. Unlike with a Lat/Long pair, we don’t know what each number in our embedding means, but we can still understand that things that are close to each other in embedding space are related.
We can create embeddings for text—that’s how things like memory work in AI applications. When an AI model appears to be learning, it's actually recalling related conversations, based on, you got it, embeddings. We can even do it for images; that’s a key to how image generation models work. First, you describe an image with an embedding that works for both text and images. Then, you can train a model to build an image with a similar meaning to the input text.
So what is AlphaEarth?
Now that we remember that embeddings are a list of numbers that represent meaning, let’s turn to AlphaEarth and see what they did:
It accurately and efficiently characterizes the planet’s entire terrestrial land and coastal waters by integrating huge amounts of Earth observation data into a unified digital representation, or "embedding," that computer systems can easily process.
(from: Google's announcement Blog)
Essentially, they computed embeddings for the Earth, akin to a sophisticated land cover dataset for the entire globe, but instead of land cover classifications, we have embeddings. (I said akin, as it is not the same as a traditional land cover dataset!) It was built using 10-meter by 10-meter squares, spanning from 2017 to 2024, resulting in a substantial amount of data.
How did they do it?
They started by breaking the Earth (land and coastline) down into 10m by 10m squares. They then gathered data from sources such as Sentinel-1 SAR, Sentinel-2, Landsat 8/9, GEDI Canopy Height, DEM, ERA5-LAND, and trained a model to generate embeddings.
To train the model, Google employed a technique known as unsupervised learning. That means they didn’t have to pre-tag the data with meaning ahead of time. Instead, they created a process that ensures similar locations generate similar outputs, allowing the training pipeline to refine them over many training runs.
Once they had the model that could generate the embeddings, they computed them for the entire Earth, and then continued computing for the entire Earth for each year from 2017 to 2024, yielding trillions of embeddings for the Earth that can be used to see locations and time.
The embedding has 64 dimensions, but don’t get sidetracked by that. It doesn’t mean that there are 64 datasets, or that one number is one dataset. It is a type of embedding—that means that those 64 dimensions (numbers) represent the meaning of the data for a single 10m by 10m square.

What can you do with it?
One thing that is important to note is that this is not a text embedding. There is no text involved; it reads the data sets directly to produce the embedding. So you can’t type in some text and have it search the Earth for you. However, you can look for similar locations or times instead.
For example, I might look at several corn fields in the central United States that have done well over the past 10 years. I could go and get the embeddings for those fields for each year and I could search for places on the Earth (location and time) that are similar. That could help me better understand crop health over time or conduct suitability analyses over larger areas.
A few other ideas:
- Urban Planning - Discover neighborhoods with similar “urban fabric”
- Conservation - Identify unprotected habitat by finding areas similar to protected zones
- Agriculture - Find similar crop environments
You could even:
➡️ Feed these embeddings into other machine learning models and create a specific model that creates land cover classifications
➡️ Then use the embeddings to generate those classifications for your city or county for the last 10 years
➡️ Look at how they have changed year over year, all without you having to create new datasets, manage a lot of imagery, or even try to run land cover AI models yourself.
So what?
While I don’t think that this, on its own, will change GIS forever, I do think it is a powerful tool and one that has yet-to-be-seen uses. Probably the most interesting things that this can do haven’t been thought of yet.
I would like to see a version of this that also works with text, allowing it to generate text descriptions of areas and find areas based on text descriptions.
I’d also like to see the model released as a tool that I can use to compute embeddings myself. Right now, Google has only released the results—the embeddings they computed—so I can’t run this model myself, on my own data.
If you want more info on this, here are a few sources that I found useful:
- Google’s overview blog with some ideas to try and more info on how it works
- The dataset description
- The announcement blog
- The paper that explains it in detail
Newsologue
- A Pizza Joint was overwhelmed by angry customers asking for Fake Deals made up by Google’s AI. Now, not only do you have to pay attention to your own AI chatbots, you have to watch out for others!
- Anthropic has been studying how cybercriminals are using AI—and it is pretty scary!
- Anthropic settles the Class Action copyright lawsuit against it; details of the settlement are still pending.
- Claude for Chrome is here, giving Claude the ability to control your browser. I’m curious to test this; so far, agents like this have been pretty terrible.
Epilogue
As with the previous posts, I wrote this post. I have been thinking and reading about Google's AlphaEarth Foundations model for a few weeks now, and I was finally ready to write this all down. There might be more in the future as I start to use it.
Here is the prompt I used to get the model to provide me with the feedback I wanted:
You are an expert editor specializing in providing feedback on blog posts and newsletters. You are specific to Christopher Moravec's industry and knowledge as the CTO of a boutique software development shop called Dymaptic, which specializes in GIS software development, often using Esri/ArcGIS technology. Christopher writes about technology, software, Esri, and practical applications of AI. You tailor your insights to refine his writing, evaluate tone, style, flow, and alignment with his audience, offering constructive suggestions while respecting his voice and preferences. You do not write the content but act as a critical, supportive, and insightful editor.
Always Identify what is working well and what is not.
For each section, call out what works and what doesn't.
Pay special attention to the overall flow of the document and if the main point is clear or needs to be worked on.
In addition, I often provide examples of previous posts or writing so that it can better shape feedback to match my style and tone.