Episode 9 - How to Find Content like you Find Places on a Map
Part 2 of a series about building a blog summarizer tool.

This is part 2 of 4 posts on building an AI-Powered Summaraizer tool:
- Episode 8 - One Summary to Rule Them All
- Episode 9 - How to Find Content Like You Find Places on a Map (this one!)
- Episode 10 - What Your Content Looks Like in Embedding Space
- Episode 11 - the Final Chunkdown - Building Smarter Summaries
Prologue
Last week, we took our first look at building a summarizer tool. The idea is to create a tool that can read hundreds of Esri blog posts and distill them into a single summary post that points me to the things that are of most interest to me.
In episode 8, we looked at how to use AI to summarize each post and rank them using an “interest score.” Then, we took the top 10 and created summaries of those summaries. But this method has a problem: the things that I am interested in are hardcoded into the initial post summary and interest score generation, which means I can’t change my mind about what I’m interested in, or share this tool (or the summaries) with someone else to use based on their interests. We need a way to fix that. Whenever I want to know about a specific product, I don’t want to re-run the entire summary process.
This week, we look at how we can use a technology called “Embeddings” to identify relationships between different texts, and we see just how similar to GIS this technique is.
Vectorlogue
In GIS, we use geocoding to turn addresses into locations; latitude and longitude. Once we have those coordinates, we can do all sorts of spatial magic: map them, compute distances, or find the 10 nearest coffee shops to your hotel.

Now, imagine we could do something like that with content.
What if we could give a paragraph of text a kind of “location” based on its meaning? We could then find the 10 summaries most related to our current interest—not just by keyword, but by concept.
That’s what embeddings let us do. They’re like geocoding, but for ideas.
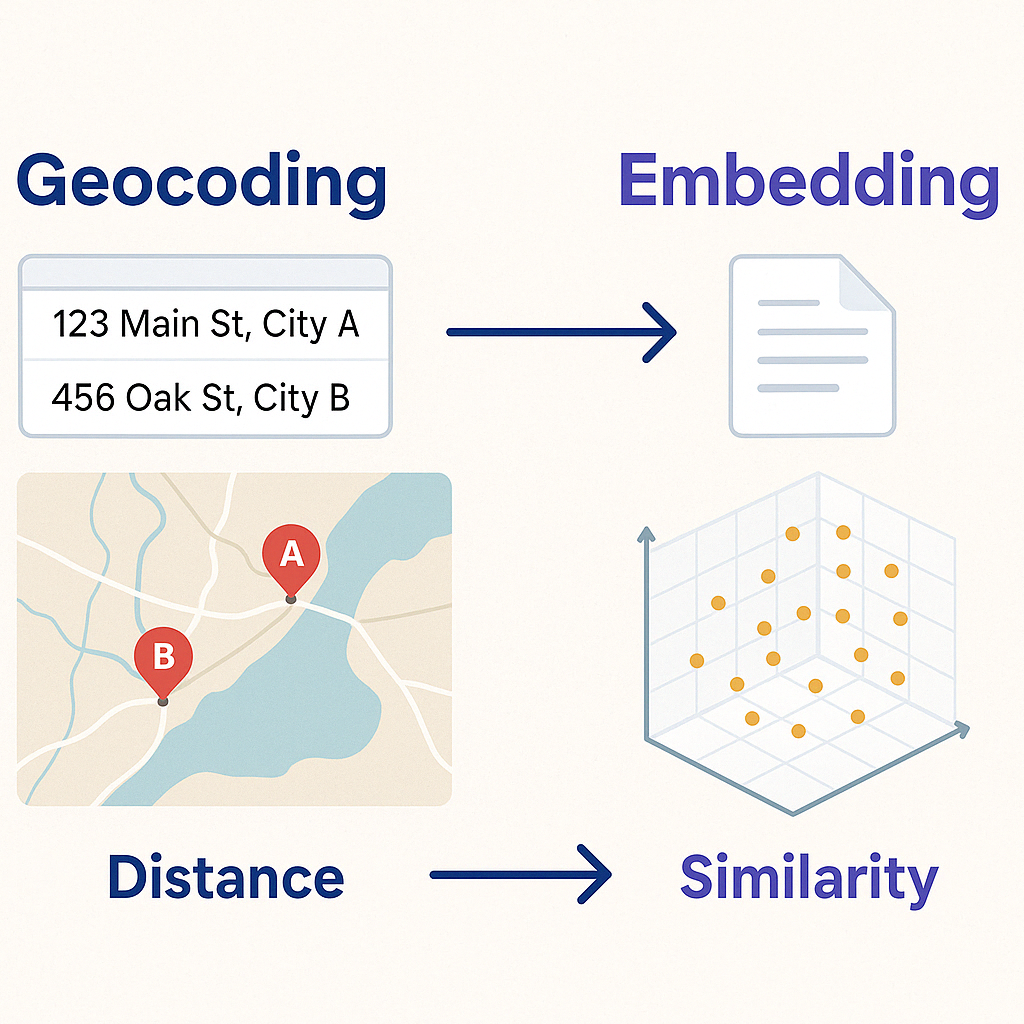
You take a bit of text, for example: a blog post summary, and run it through an embedding model. The output is a list of numbers (a vector) that places that text in a multi-dimensional “meaning space.”
From there, everything else works like GIS:
- Summaries that are “closer together” are more similar in content.
- You can compute distances, cluster content, find “nearest neighbors,” or even filter by conceptual radius.
Same mechanics. Different space.
Ok, but what are Embeddings really?
Embeddings are vectors (long lists of numbers) that represent the meaning of a piece of text. This isn’t a full-text search or a database “like” statement. You pass a sentence, paragraph, or document through an embedding model, and get back a vector that captures the “meaning” of that input. You can then compare it to other texts by calculating how far apart they are in embedding space.
It’s like converting addresses to coordinates. Once you have those coordinates, you can measure distance. Same idea here, just with concepts instead of locations.
Embedding Examples
Embeddings represent the meaning of the text they are generated from, not just the words themselves. This allows us to search based on meaning, and, as in geography, words or sentences that are closer in meaning will have closer embeddings.
Since an Embedding represents the meaning of the text, we can find movies that are similar to other movies by comparing embeddings of their scripts. Netflix uses processes like this to find movies or shows you might like based on ones that you already do.

The same can be said for songs, images, or even ads (yuk)—once I know something you are interested in or liked, I can use embeddings to find similar things in the hope that you will like those things, too.
Embedding Summaries
We can use this embedding process on our summaries! We start by creating an embedding for each summary. Then, when the user asks for something specific, we create an embedding of that request too. Then, we can easily search for the top ten summaries that are closest in subject or meaning to what the user requested.
Building the Next Summary App
The goal is to update our existing tool. Here’s how we want this to work:
- For each blog post summary, we’ll generate an embedding using a consistent model (very important—you can’t mix and match embedding models, or your distances won’t mean anything. Just like you can’t mix and match projections!).
- We’ll remove the interest scoring step from the summarizer prompt and just get the raw summary without judging its value, making the process reusable.
- The prompt that summarizes each post also needs to be updated. We want it to generate as generic a summary as possible, not one tailored to our specific interests but a general summary of the post.
- Then, when we want to build a new summary blog, we type in a quick paragraph or list of what we’re looking for,like “recent changes to ArcGIS APIs and SDKs related to performance.”
- We convert that input into an embedding.
- Then, we find the 10 closest blog summaries (Most embedding tools default to cosine similarity, which works well for comparing meaning).
- And finally, we hand those 10 closest summaries over to the LLM to generate our composite summary.
We can do this with minimal changes to the app we built in Episode 8. It’s just a few updates:
- Repair our summary prompt to be more generic.
- Use a REST API for the embeddings. OpenAI has one. Anthropic doesn’t (yet), but they recommend one I’ve used before, Voyage AI. You can also run a local model if you’ve got a lot of data.
- Always ensure all embeddings are created with the same model version or you’ll have to regenerate them all from scratch.
- Then, we write a new function to take a user input string, get its embedding, compare it to our stored summaries, and grab the most relevant ones.
These vectors get saved alongside your summaries in a JSON file, structured with fields for title, summary, url, and embedding vector.
{
"title": "What's New in ArcGIS Maps SDK",
"summary": "This post covers recent performance improvements and ....",
"url": "https://blogs.arcgis.com/whats-new-in-arcgis-maps-sdk",
"embedding": [0.0243, -0.517, 0.134, ...]
}
That’s it. The architecture is nearly identical to before—we’re just swapping out how we select “interesting” posts.
Generate the design document
As with last week, we need a design document. I used a draft of this post in the existing thread I had with Claude 3.7 about the previous design document:
<PASTE BLOG DRAFT HERE>
That gives us our design document.
As before, I used the design document to ask Claude to write the code updates. We could use something like Codebuff to do this, but I already had Claude build the previous app, and I think these changes are pretty minor:
<PAST DESIGN DOC HERE>
It worked almost perfectly. There was one issue in the embeddings API call, but Claude was able to correct it just based on the error message. From there, everything worked.
Using this app for yourself
If you want to personalize your own AI summarizer, all the source code is on GitHub. A live version runs on Replit, so you can immediately clone, modify, and experiment.
Remember that, as I mentioned above, this summary process can hide data that might be useful. For example, if a blog buries a key point, like a new release announcement, in the last paragraph that doesn’t make it to the summary, we would miss that blog when looking for a summary of “new software releases.” The main way to fix that is with full-on RAG.
Even with that shortcoming, though, this is a fantastic way to make a lot of data searchable and summarizable in a helpful way. You could also apply this to other things, like:
- Providing executive summaries of lots of projects.
- Summarizing blogs across many different sites that specialize in your industry.
- Summaries of corporate documents.
- Summaries of product documentation.
Want to see what your blog’s content universe looks like? Tools like UMAP or t-SNE can reduce these vectors into 2D plots that let you map your summaries like pins on a conceptual map.
Spoiler Alert: That's next week!

You are even on the path toward building a custom chatbot that can answer questions about your tools or products!
Let me know in the comments if you'd like to see how that works!
Newsologue
- Action Figure Trend on Linkedin
- OpenAI releases a Codebuff Competitor. I'm excited because the tool is open source
- OpenAI releases new models, maybe they catch up to Claude 3.7 because they think with images
Epilogue
I did something different for this episode. I recorded these thoughts on my Limitless.ai pin and used the same content editor AI that I used on Episode 8 to turn the transcript into a draft. From there, I re-wrote most of it, including more detail. Some things did make it from the AI draft, like the bullet points in the “Building the Next Version” section.
This also highlights one of my favorite things about AI right now—it’s giving us new ways to think, build, and even write. We’re building tools to help us think better about what we already care about.
Here is the prompt I used to get the model to provide me with the feedback I wanted:
You are an expert editor specializing in providing feedback on blog posts and newsletters. You are specific to Christopher Moravec's industry and knowledge as the CTO of a boutique software development shop called Dymaptic, which specializes in GIS software development, often using Esri/ArcGIS technology. Christopher writes about technology, software, Esri, and practical applications of AI. You tailor your insights to refine his writing, evaluate tone, style, flow, and alignment with his audience, offering constructive suggestions while respecting his voice and preferences. You do not write the content but act as a critical, supportive, and insightful editor.
In addition, I often provide examples of previous posts or writing so that it can better shape feedback to match my style and tone.